
Summary
I collect VHS tapes. Standing in front of 200 random tapes at a flea market, trying to decide what's worth grabbing, is a real problem. Do I already own that? Is it any good?
So I built Rewind. You photograph a stack and the app tells you what fits your taste, flags what you already own, and surfaces stuff you'd normally walk right past. I designed it as a thrifting tool. Users turned it into a collection platform, scanning hundreds of tapes at home and asking for features I hadn't considered. So I pivoted.
Built solo in ten weeks, monetized two weeks after launch.
This is the first [app] that immediately sucked me in. I scanned my entire collection (over 500 tapes) and got all my 'want list' on there, all in the first night. Now I play on it once or twice a day. The aesthetic is so good and everything is so smooth. 10/10
How it started
The idea hit over the holidays. I was home in the Midwest visiting a friend who collects VHS tapes. I was looking over his eclectic shelves and a lightbulb came on: what if I documented his collection, fed it into an LLM to generate a taste profile, and used that to identify tapes I might not be familiar with when I'm out thrifting?
I tried a quick and dirty version, feeding the taste profile I'd generated into ChatGPT as a seed and then sending it pictures of tape stacks at flea markets. It kind of worked, but it was pretty rough. After a few exchanges it would start re-recommending tapes I'd already scanned or hallucinating titles that didn't exist. I'd have to start over in a new chat, burning tokens like crazy. Chat turned out to be the wrong format for this. I realized that for accuracy, an LLM needed to be fed the profile fresh every time, and that it was overkill to use a frontier model just for image recognition. I needed to decouple these things. I needed an app.
Weekend prototype
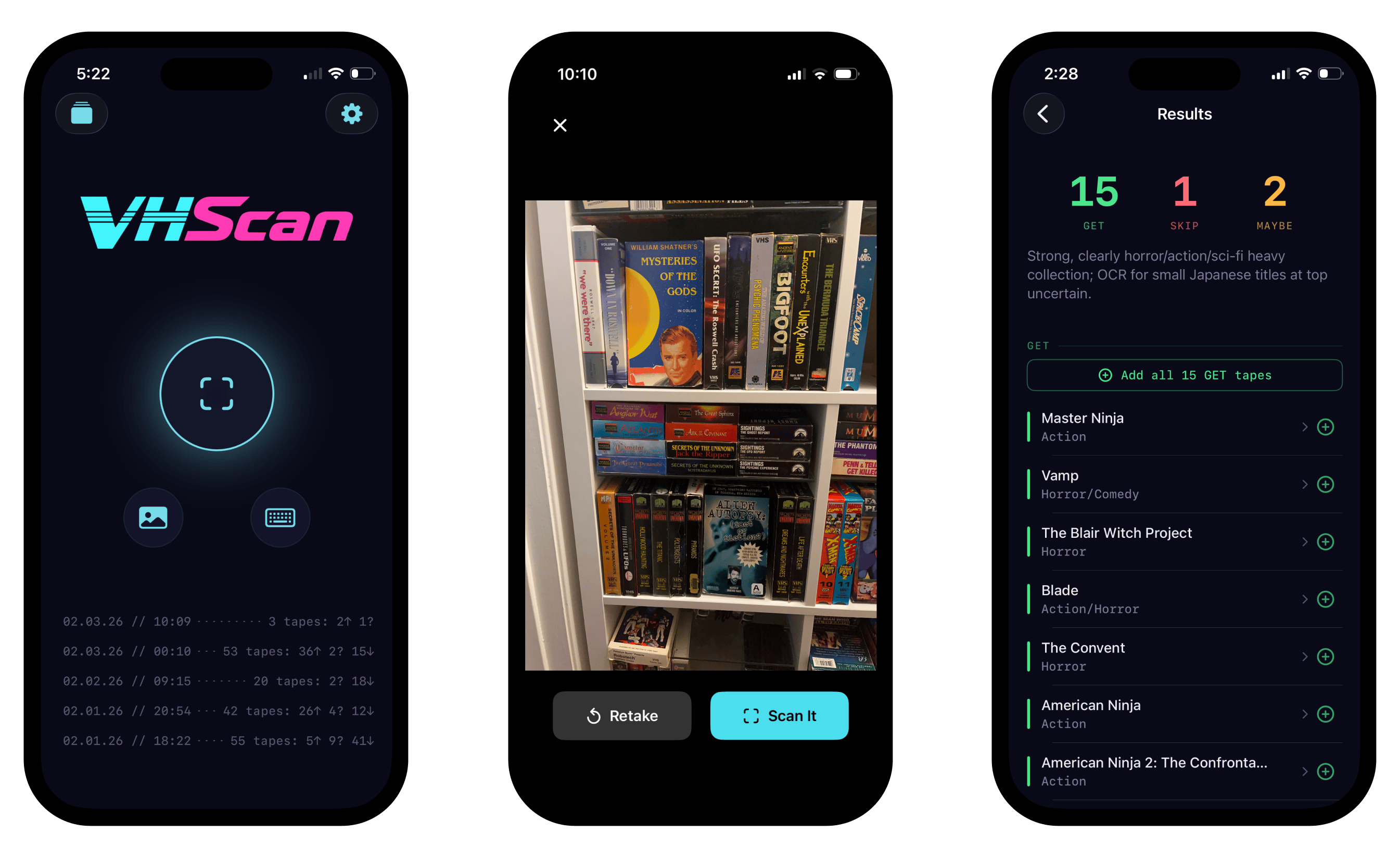
I put together a prototype over a weekend, building it out with Claude Code in Swift. I fed in collection data from a spreadsheet so I could determine if I owned a tape or not. I used a cheaper model for rough OCR, and I used a more capable model to evaluate each recognized tape against the stored taste profile. I built out a basic pipeline on Cloudflare. And.. it worked! The improvement in accuracy was staggering. But it was very slow and very expensive. Regardless, it was enough to start testing with real users.
Market research & product strategy
Rapid community research
While building the prototype, I scraped the communities where collectors hang out. Reddit, Instagram, TikTok, Facebook. Thousands of posts and comments. I wanted to understand how collectors talked, who the influential voices were, and what got people to engage.
Community discussion analysis
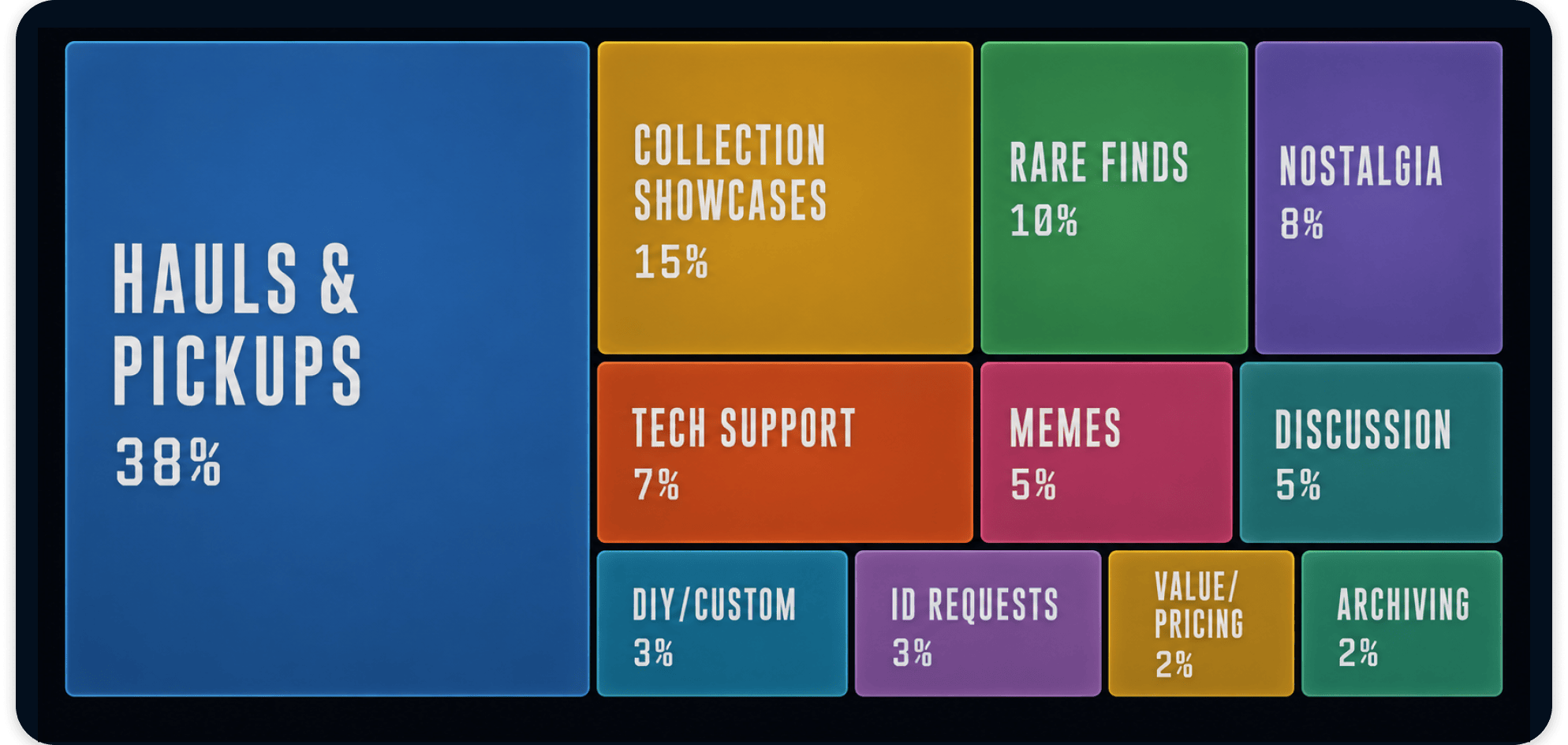
I kept seeing the same five types of collectors. Some want the movies they grew up with. Some are preserving tapes that never made it to digital. Different reasons, different criteria. But every single one of them has accidentally bought the same tape twice.
The technical bet was simple. AI was already good at OCR. If I paired that with a database and your synced collection, you could photograph a whole stack of tapes and get answers for all of them at once. Every collecting app on the market made you go one by one via UPC code. Most VHS tapes don't even have barcodes. Stack scanning sidesteps both problems.
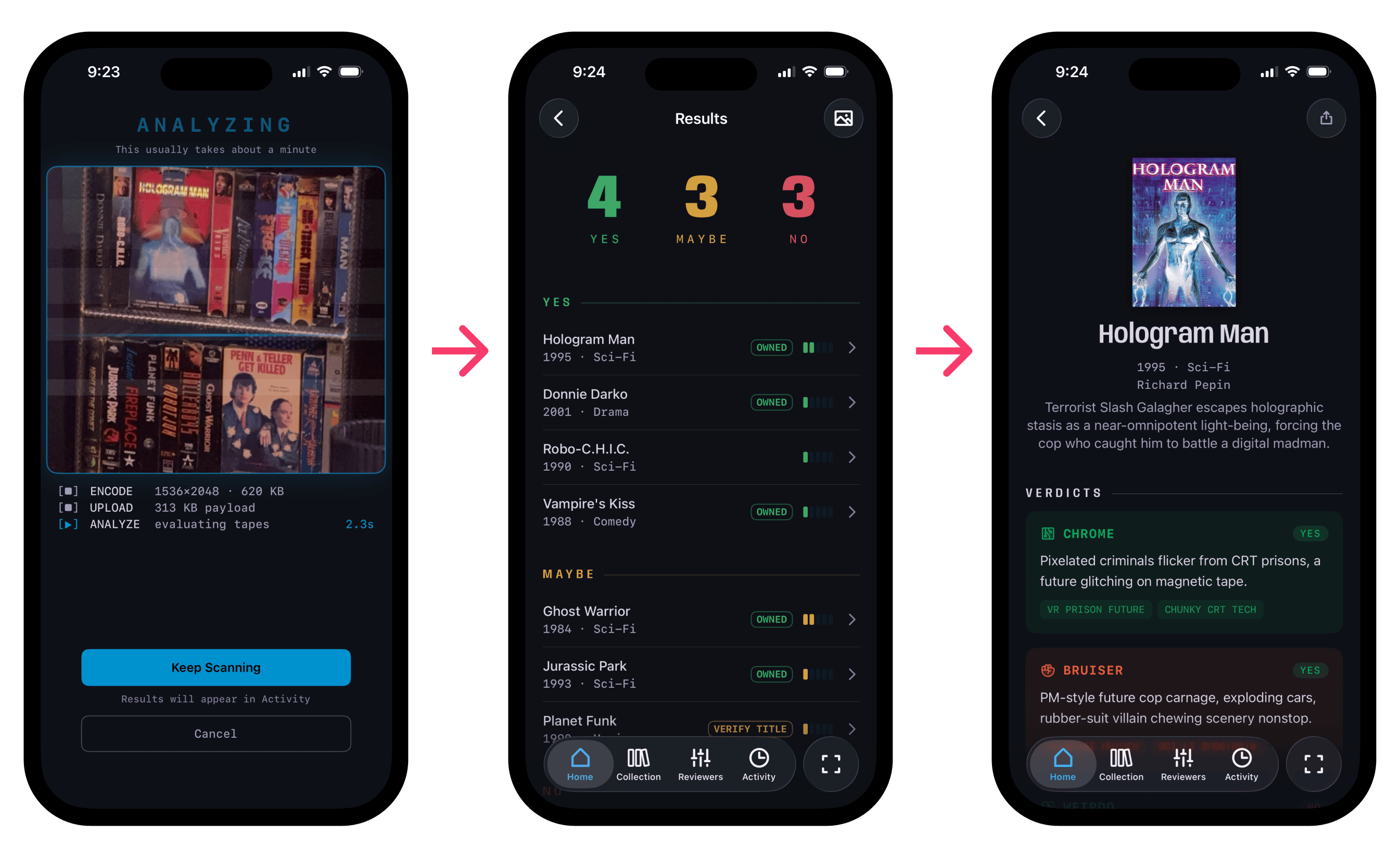
After launch, the data backed this up. Out of nearly 800 scans, exactly one was a manual text entry. Everyone else used the camera.
An opportunity
Scanning a stack tells you what you're looking at. It doesn't tell you what's worth picking up. If you're standing in front of 200 tapes, you need both.
Everything else on the market picked one side. Price-checking apps turned every thrift store trip into a reselling exercise. The community hated them. Collection managers let you catalog what you owned but couldn't tell you anything about a tape you'd never seen before. One collector summed it up: "There has been an empty hole in the market for a good app that can do this that's reliable."
Pricing benchmarks from wine scanning, film logging, and trading card apps showed the range. Thrift-culture hobbyists won't pay enterprise prices, but they'll pay for something that respects the hobby.
The product
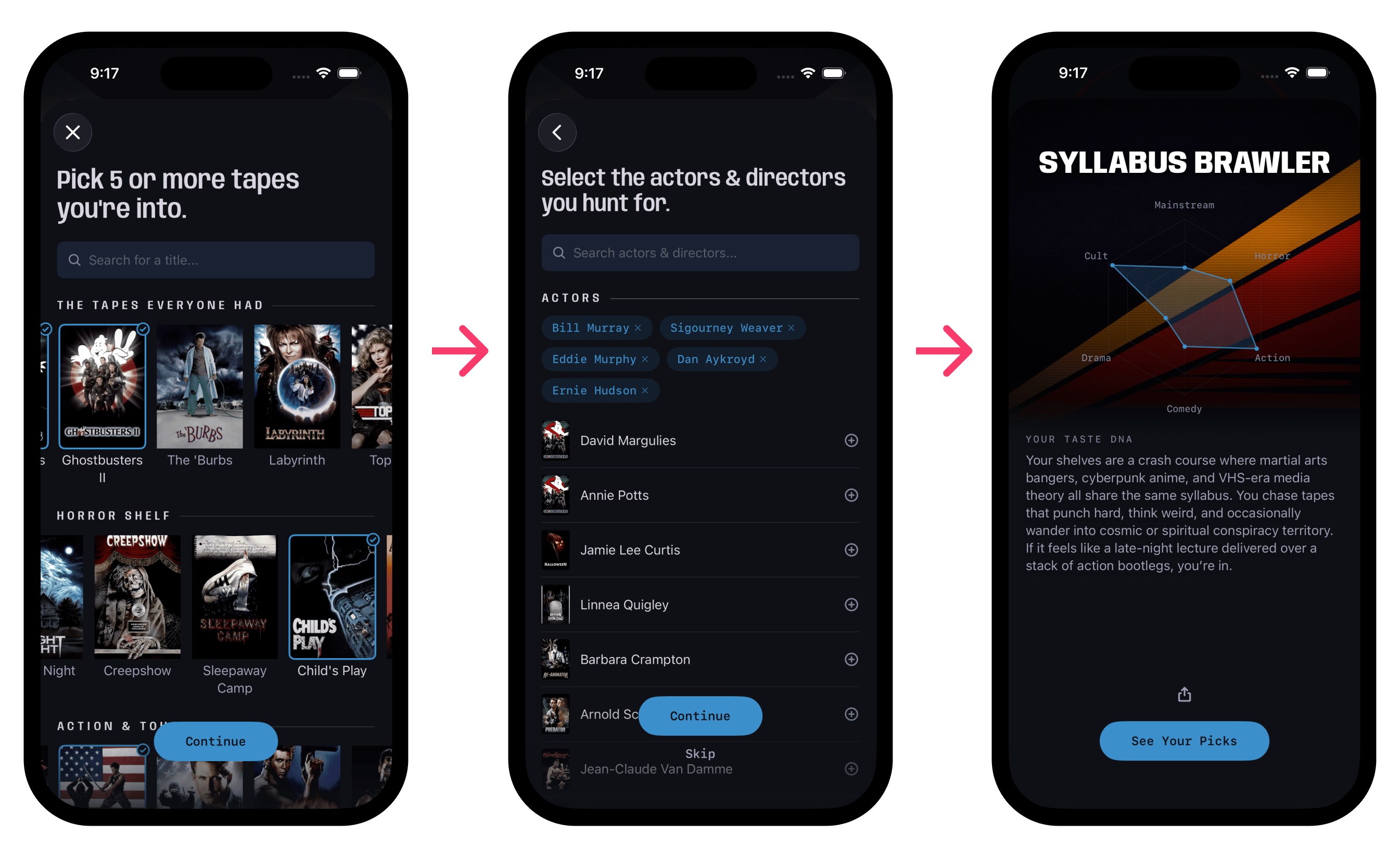
The prototype started with rubrics modeled on friends' tastes. I have a buddy who only cares about horror distribution labels. Another who collects anything cyberpunk. A third who wants every tape that was banned, censored, or pulled from shelves. Each of them would look at the same bin of tapes and reach for completely different ones.
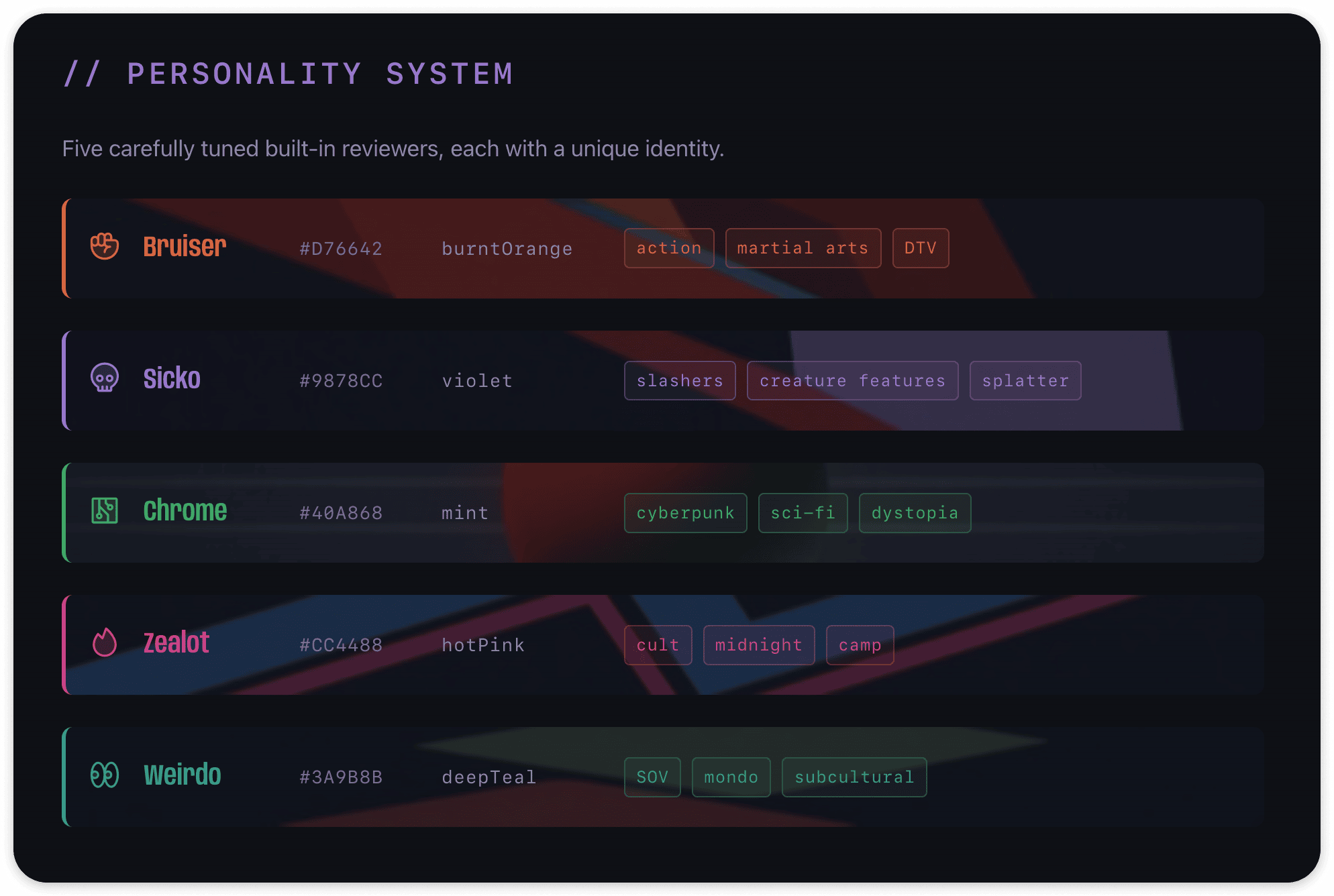
So instead of one AI giving you an overall score, five reviewers evaluate every tape: Bruiser, Sicko, Chrome, Zealot, and Weirdo. Each has a completely different take on what makes a tape worth having. They disagree constantly, and that's the point. You're not checking a number. You're reading five short takes from reviewers who care about different things.
It turns a utility into something more interesting.
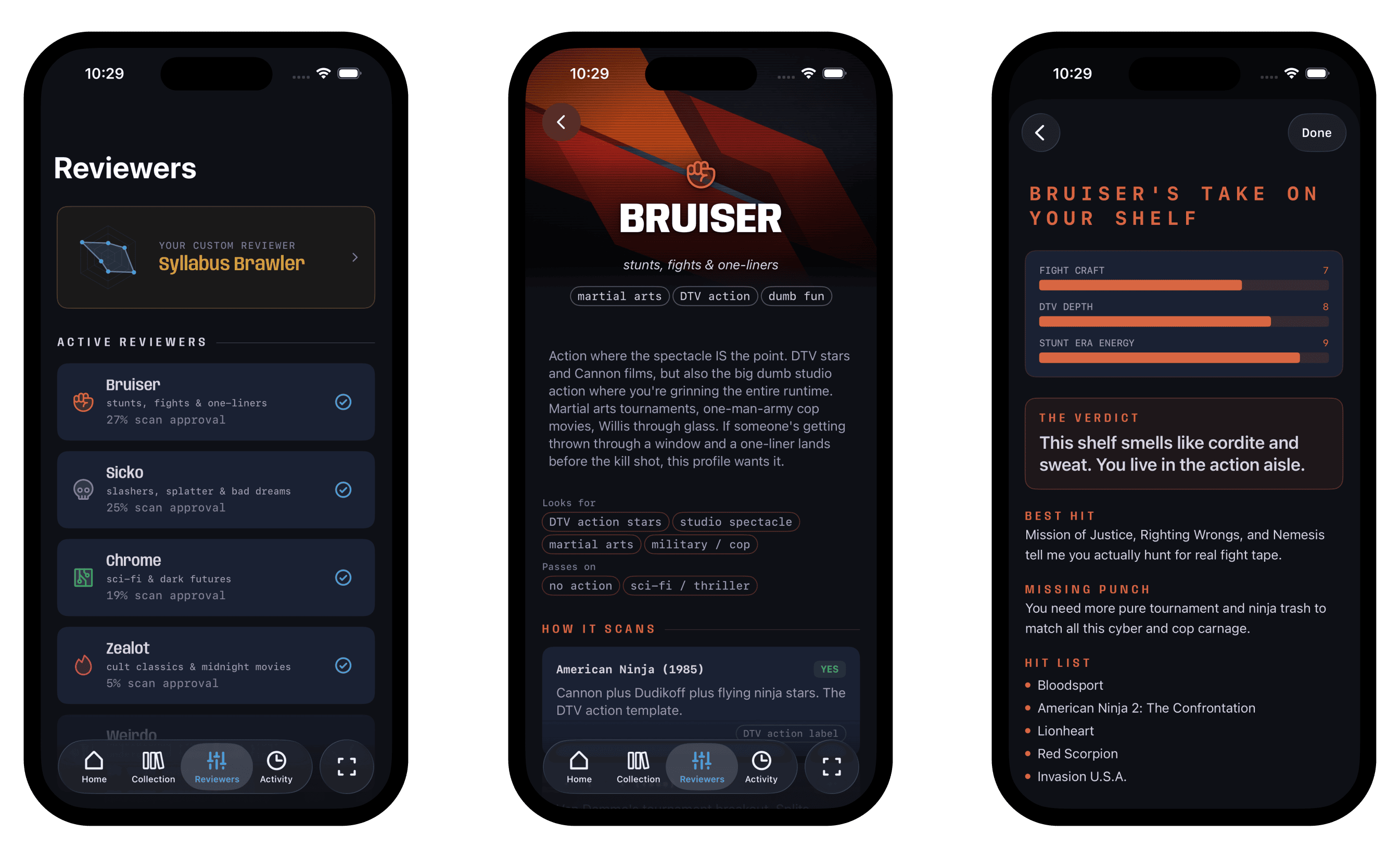
Custom profiles
The logical extension of the built-in reviewers is personalization, so I created a builder that allows you to create your own custom reviewer. It captures what you collect, what you avoid, and how you think about taste. It generates a custom reviewer that's tuned to you specifically.
The builder only requires five tapes to move forward, but most users selected dozens. A few picked over a hundred. 67% of users who started the flow finished it.
Server-side architecture
All AI processing runs remotely. No API keys on the device, no model dependencies baked into the app binary. The pipeline has two stages so I can change how reviewer evaluation works without pushing an app update. As new and better models come out, I can swap them out easily.
Design system
The visual direction came from the tapes themselves. Blank VHS packaging from the 80s and 90s. Dark backgrounds, bold type, that specific shade of blue-black. I built a full design system around it called Cyberdelia. Personality tints for all five reviewers, custom backdrops per reviewer and genre, a CRT scanline overlay with adaptive frame rates and a reduced-motion kill switch, and condensed type that reads like a VHS spine.
Data foundation
Mainstream databases cover the big releases fine. But VHS is its own world. Distributor exclusives, regional variants, dollar-bin anime, titles that never made it to any other format. If my database doesn't have a tape, the app can't properly identify it.
AI-assisted data pipelines allowed me to build out a proprietary catalog covering VHS-specific titles most mainstream databases miss.
Some of the source material is from public databases. Some is from physical materials and offline sources that can't be scraped from the web. Some of it was contributed by kind members of the VHS community. The pipeline handles all of it through OCR and AI-structured parsing.
Dashboards
I needed good data to make good product decisions. So I built two dashboards.
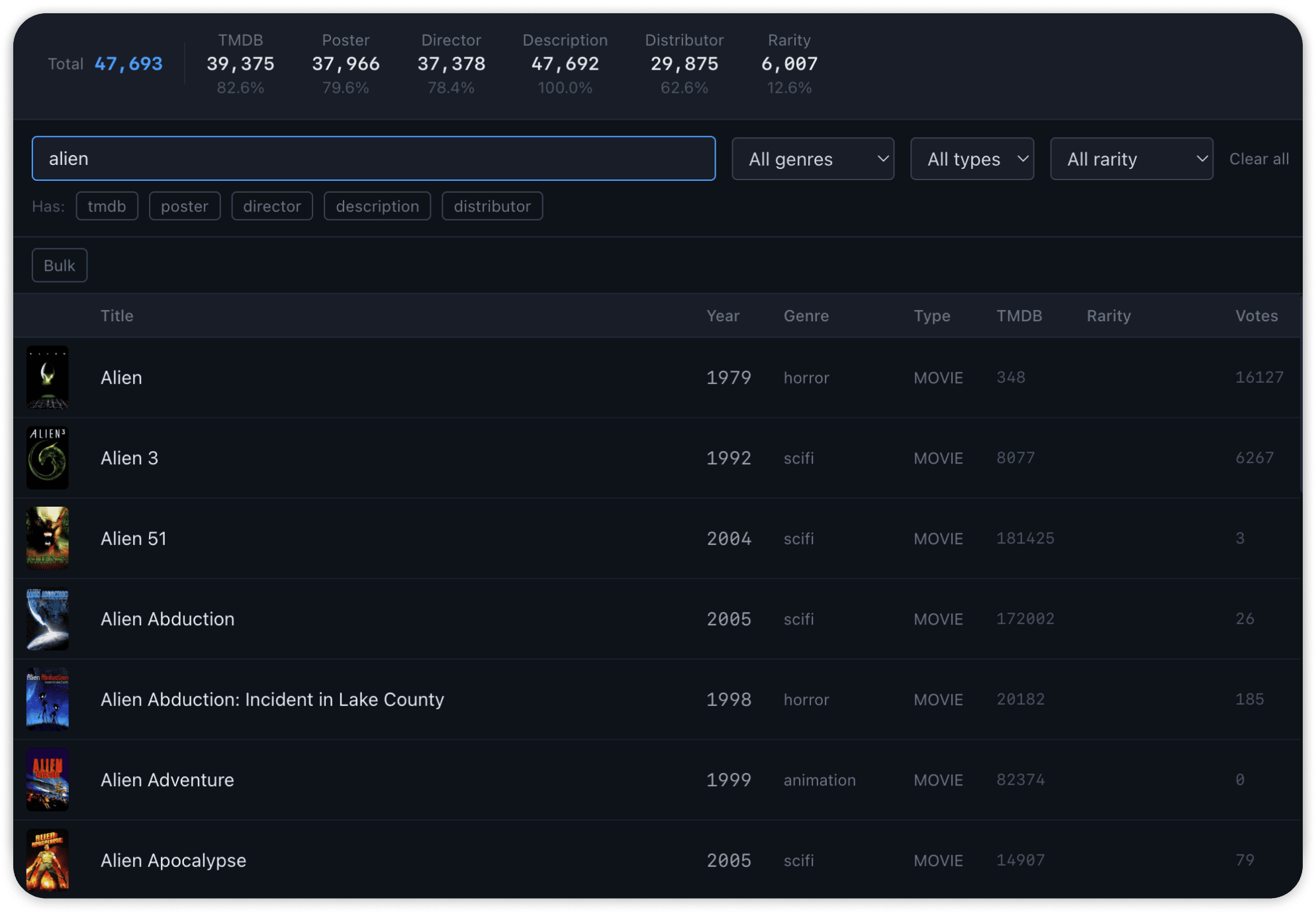
The admin dashboard is where I manage the catalog. Every title is browsable, filterable, and editable inline. Quality monitoring flags coverage gaps and data problems across the full database. There's a review queue for ambiguous matches, because VHS data is messy and sometimes the pipeline needs a human call. When the catalog is ready, a publish step shows me exactly what changed before I push it out to users.
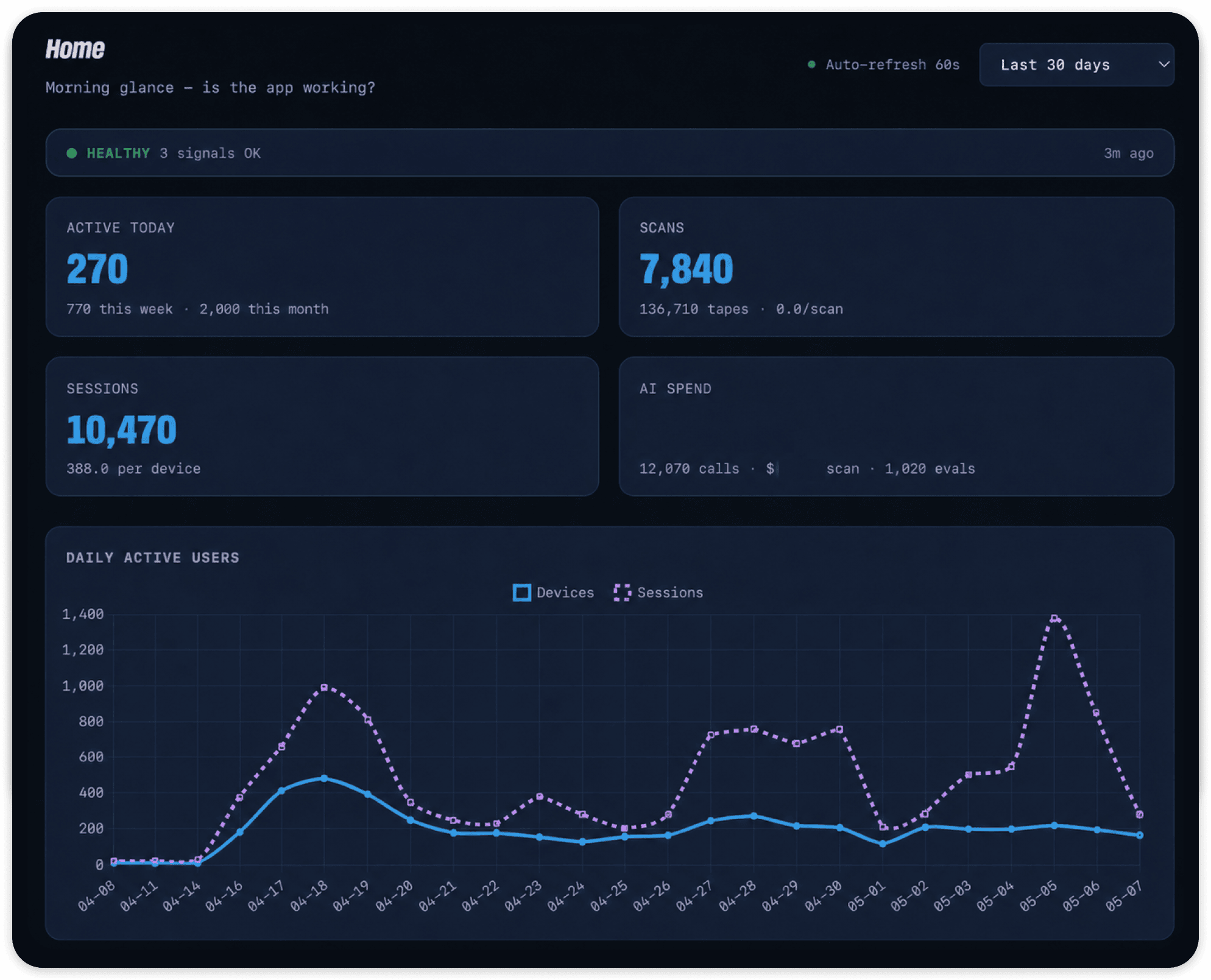
I needed to see what people actually did in the app from the moment it went live. So the analytics dashboard goes a lot deeper. I can see how people move through a scan, from taking the photo to adding something to their collection, and where they drop off. I can see who comes back the next day and who doesn't. There's a whole layer for the reviewers. Which personality is the pickiest, how often they agree with each other, and when users disagree with a verdict so I know what to adjust. On the ops side I'm tracking AI costs and pipeline speed so nothing surprises me. And instead of building a new view every time I have a question, I wired up Gemini to let me query the full database in plain English.
I built both dashboards before launch. The pivot proved that was the right call.
Pivoting
Beta launch
I launched the app on TestFlight and posted the beta on r/VHS. The post got 15k views and 63 people signed up to test it. "Never downloaded an app so fast," one commenter wrote. Another: "This is super cool! As someone just starting my collection, this is exactly what I've been looking for. Libib and CLZ were just too clunky."
I also approached members of the Austin VHS scene while field testing the app to see if they would be interested in joining the beta. Several were incredibly enthusiastic, and I was able to do guerrilla testing on features I was prototyping with my actual target users.
Real people were using it. The analytics dashboard let me watch what they did, and the testers gave me direct feedback. Ship update, watch usage shift, ship the next one.
Four weeks later, I submitted to the App Store.
Post-launch signal
After launching to the App Store and announcing it in various channels, my post-launch data told an interesting story.
People were using the feature. But they were primarily using the app in a way I hadn't anticipated. The power users weren't at Goodwill deciding whether to grab something. They were sitting at home, scanning their collections.
In half an hour I had 605 tapes scanned in. I was self-checking the consistency against the hand-typed excel sheet that took me a weekend to put together, and your app produces more information per line item.
The scanning feature — especially the collection scanning feature — was a big hit. But where I'd built a thrifting tool, my target users had found a collection management platform.
The extraction data backed that up. Users removed 40% of recognized tapes during review, and only 3% ever hit "accept all." They were carefully curating their libraries, not just dumping everything in.
30% came back on day two with zero re-engagement features. No push notifications, no email, nothing pulling them back. They returned because they had more tapes to add.
New direction
The product I'd built for thrifting was being used for collecting. I leaned into that, building several quality of life collection management features and sending an update to the beta testers. I could see users using the features immediately in the analytics dashboard I'd built, even without any sort of callout.
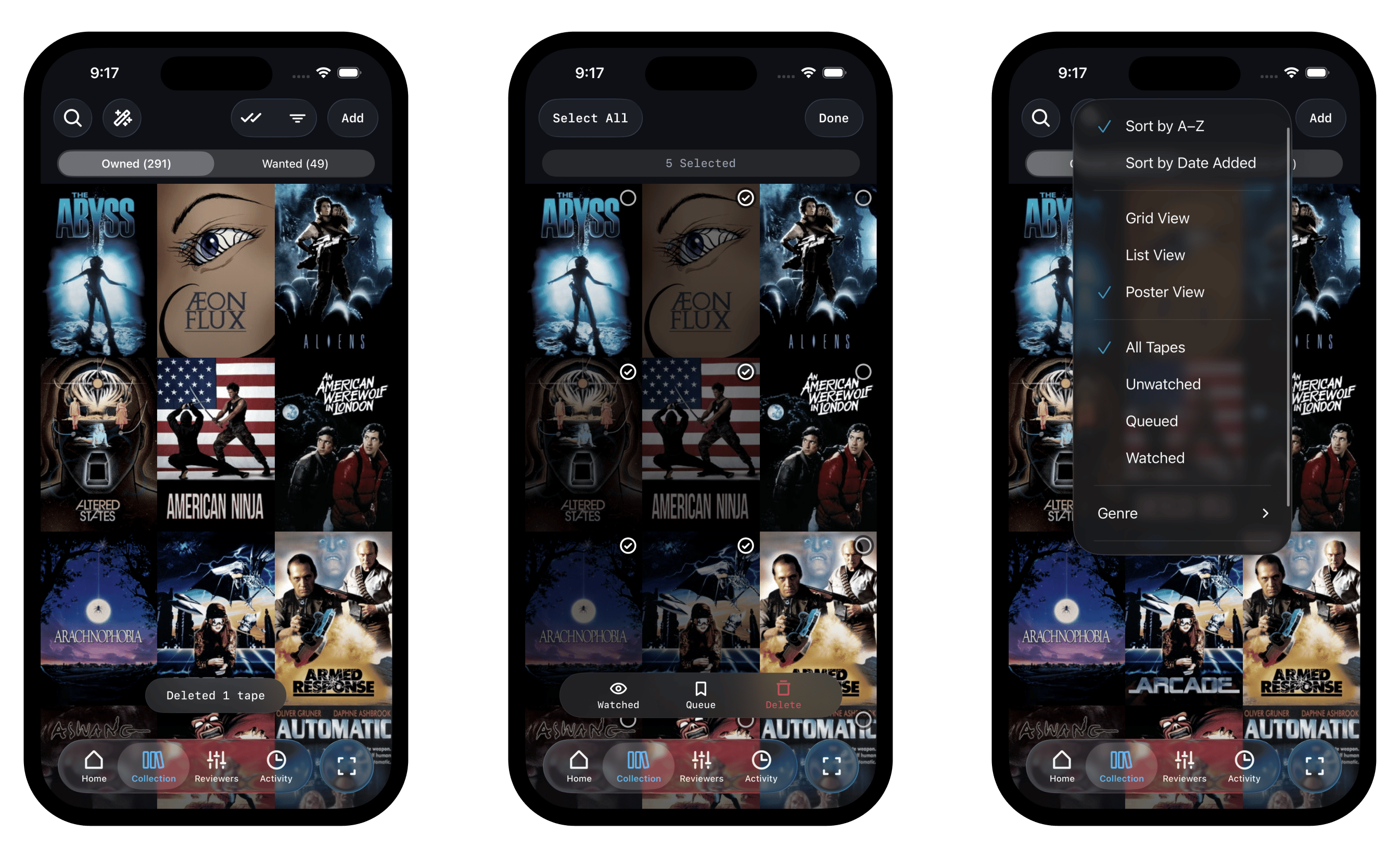
In addition to the collection-centric data, I also got a signal via user feedback and community comments that users wanted to track and rate what they watched, not just catalog it. The existing collecting apps didn't do that, and people were adding their VHS collections to Letterboxd lists as a workaround. That's the gap, and that's where I decided to go. Letterboxd for physical media, with AI taste intelligence built in.
The post-launch data pointed in the same direction. Usage of "what should I watch tonight" features grew 50-65% week over week, without any nudging.
Survey data showed that 79% of users also collected DVD, Blu-ray, or LaserDisc. Clearly centering my app around VHS was leaving broad swaths of users on the table. So, I started building out multi-format capabilities.
Monetizing a price-sensitive community
Scanning is how people find the app. The collection is why they stay. For a price sensitive community, you can't realistically charge for either.
It took three tries to land on what people would pay for. First I tried scan limits and collection caps, which is the angle my competition takes. Users who hit any limit just stopped using the app. Then I tried locking the custom reviewer behind a paywall. Closer, but in testing I realized the profile builder itself was the hook. Gating that took away something of real value.
So now the builder is free. You build your reviewer, see what it produces, get invested in it. Subscribing activates it across the app. That's the version that clicked.
The usage data showed why it worked. Preset reviewers recommend roughly 3.5% of the tapes they evaluate. A custom reviewer recommends about 25%. Scan a shelf with your profile active and you can feel the difference immediately.
The VHS collecting community has thrift-culture pricing expectations and deep hostility toward anything extractive. Patterns from bigger apps just didn't translate.

What I Learned
Build what users do, not what you designed for. The scanning thesis was technically right. The AI pipeline worked, scans succeeded 99%+ of the time. But users had a different idea of what the product was for. Being wrong about that was the best thing that happened to it. It's also the fun part.
Constraints are features. No prices, no resale data, no flipper energy. I thought that would limit the app. It ended up defining it. Every app in this space built with flipping in mind gets attacked by the community. Every app that shows taste gets embraced.
AI tools change what one person can ship. I built the catalog pipeline, the dashboards, the design system, and the iOS app in ten weeks because Claude Code did the heavy lifting on code. The judgment work, what to build, what to skip, what to throw away when the launch data came in, is still entirely human.
"This is what AI should be for," one user wrote. "Giving me a library of all my VHS tapes at the press of a button, with all the bells and whistles of a curated paid service."

